DoCA: A Content-Based Automatic Classification System Over Digital Documents
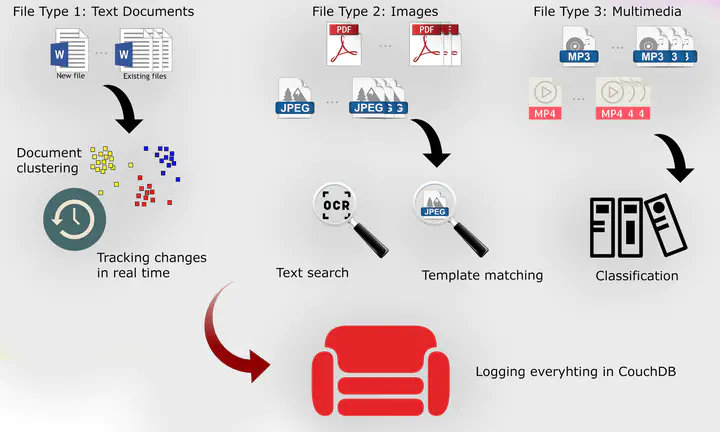
Regardless of industry, the overload of information facing most organizations today is a drain on both individuals and the enterprise itself. The increasing volume of this information, which is stored in different electronic formats, requires new sophisticated systems to analyse and classify them. In this paper, we attempt to implement a framework for Document Classification and Analysis (DoCA) that can simplify and automate such tasks for different file types, namely: office documents (text, spreadsheets, and presentations), scanned documents (images and PDFs), multimedia files (video and audio). Each file type requires different methods for pre-processing, analysis, and classification. The efficiency and feasibility of the DoCA are examined on HAVELSAN dataset and accuracy of different tasks shows that the DoCA is a promising tool for document analysis and classification.